In July last year, Ilya Segalovich passed away, founder and director of technology at Yandex, creator of the first version of the search engine and author of its name. In memory of this outstanding person and public figure, who helped many, includingCOLTA. EN, we publish it about information retrieval and the mathematical models that underlie it. Ilya Segalovich called search engines one of the two new wonders of the world. In any case, without them, including without the main brainchild of Segalovich - Yandex, our life would be completely different.
Hundreds of search engines have been written in the world, and if you count the search functions implemented in a variety of programs, then you need to keep count of thousands. And no matter how the search process is implemented, no matter what mathematical model it is based on, the ideas and programs that implement the search are quite simple. Although this simplicity belongs, apparently, to the category about which they say "simple, but it works." One way or another, but it was search engines that became one of the two new wonders of the world, providing homosapiens unlimited and instant access to information. The first miracle, obviously, can be considered the Internet as such with its possibilities of universal communication.
Search engines in historical perspective
There is a common belief that each new generation of software is better than the previous one. They say that before everything was imperfect, but now almost artificial intelligence reigns everywhere. Another extreme point of view is that "everything new is a well-forgotten old". I think that in relation to search engines, the truth lies somewhere in the middle.
But what has actually changed in recent years? Not algorithms, not data structures, not mathematical models. Although they do too. The paradigm of using systems has changed. Simply put, a housewife, looking for a cheaper iron, and a graduate of an auxiliary boarding school, hoping to find a job as an auto mechanic, sat down at the screen with a search line. In addition to the emergence of a factor that was impossible in the pre-Internet era - the factor of the total demand for search engines - a couple of changes became obvious. First, it became clear that people not only “think in words”, but also “seek with words”. In the system's response, they expect to see the word typed in the query string. And secondly, it is difficult to “retrain a person who seeks” to seek, just as it is difficult to retrain to speak or write. The dreams of the 1960s and 1980s of iterative query refinement, natural language understanding, search by meaning, and generation of coherent answers to questions are now hard-pressed by reality.
Algorithm + data structure = search engine
Like any program, a search engine operates on data structures and executes an algorithm. The variety of algorithms is not very large, but it is. Apart from quantum computers, which promise us a magical breakthrough in the "algorithmic complexity" of search and about which the author knows almost nothing, there are four classes of search algorithms. Three of the four algorithms require "indexing", the pre-processing of documents, which creates an auxiliary file, that is, an "index", designed to simplify and speed up the search itself. These are algorithms of inverted files, suffix trees, signatures. In the degenerate case, there is no preliminary stage of indexing, and the search occurs by sequential scanning of documents. Such a search is called direct.
Direct Search
Its simplest version is familiar to many, and there is no programmer who would not write such code at least once in his life:
Despite its apparent simplicity, direct search has been intensively developing over the past 30 years. A considerable number of ideas have been put forward that reduce the search time by several times. These algorithms are described in detail in a variety of literature, there are summaries and comparisons. Good reviews of direct search methods can be found in textbooks such as Sedgwick or Corman. At the same time, it should be taken into account that new algorithms and their improved versions appear constantly.
Although direct browsing of all texts is a rather slow exercise, one should not think that direct search algorithms are not used on the Internet. Norwegian search engine Fast used a chip that implements the logic of direct search for simplified regular expressions (fastpmc) , and placed 256 of these chips on one board. This allowed Fast serve a fairly large number of requests per unit of time.
In addition, there are many programs that combine an index search to find a block of text with a further direct search within the block. For example, very popular, including in Runet, Glimpse.
In general, direct algorithms have fundamentally win-win distinctive features. For example, unlimited possibilities for approximate and fuzzy search. After all, any indexing is always associated with the simplification and normalization of terms, and, consequently, with the loss of information. Direct search works directly on original documents without any distortion.
Inverted file
This simplest data structure, despite its mysterious foreign name, is intuitively familiar to any literate person, as well as to any database programmer who has not even dealt with full-text search. The first category of people knows what it is, according to "concordances" - alphabetically ordered exhaustive lists of words from one text or belonging to one author (for example, "Concordance to the poems of A.S. Pushkin", "Dictionary-concordance of F.M. Dostoevsky's journalism" ). The latter deal with some form of postings list whenever they build or use a "database index by key field".
Let us illustrate this structure with the help of a wonderful Russian concordance - "Symphony", issued by the Moscow Patriarchate based on the text of the synodal translation of the Bible.

We have an alphabetically ordered list of words. For each word, all "positions" in which this word occurred are listed. The search algorithm consists in finding the desired word and loading into memory an already expanded list of positions.
To save on disk space and speed up the search, two tricks are usually resorted to. First, you can save on the details of the position itself. After all, the more detailed such a position is given (for example, in the case of the Symphony it is “book + chapter + verse”), the more space is required to store the inverted file.
In the most detailed version, in the inverted file, you can store the word number, and the offset in bytes from the beginning of the text, and the color and size of the font, and much more. More often, they simply indicate the number of the document (say, a book of the Bible) and the number of occurrences of this word in it. It is this simplified structure that is considered the main one in the classical theory of information retrieval - InformationRetrieval(IR) .
The second (not related in any way to the first) compression method: arrange the positions for each word in ascending order of addresses and store for each position not its full address, but the difference from the previous one. Here is how such a list would look like for our page, assuming that we remember the position up to the chapter number:
In addition, some simple packing method is imposed on the differential way of storing addresses: why give a small integer a fixed “huge” number of bytes, because you can give it almost as many bytes as it deserves. Here it is appropriate to mention Golomb codes or the built-in function of the popular language Perl: pack("w») .
In the literature, there is also a heavier artillery of packing algorithms of the widest range: arithmetic, Huffman, LZW etc. Progress in this area is ongoing. In practice, they are rarely used in search engines: the gain is small, and processor power is spent inefficiently.
As a result of all the tricks described, the size of the inverted file, as a rule, is from 7 to 30 percent of the size of the original text, depending on the addressing details.
Listed in the "Red Book"
Algorithms and data structures other than inverted and forward searches have been repeatedly proposed. These are, first of all, suffix trees (Manber, Gonnet), as well as signatures (Faloutsos).
The first of them also functioned on the Internet, being a patented search engine algorithm. open text. I have seen suffix indexes in domestic search engines. The second - the signature method - is the transformation of the document to block tables of hash values of its words - "signature" and sequential viewing of "signatures" during the search.
Neither method was widely used, and therefore did not deserve a detailed discussion in this short article.
Mathematical models
Approximately three out of five search engines and modules function without any mathematical models. More precisely, their developers do not set themselves the task of implementing an abstract model and / or are unaware of its existence. The principle here is simple: if only the program finds something. Aby how. And then the user will figure it out.
However, as soon as it comes to improving the quality of the search, about a large amount of information, about the flow of user requests, in addition to empirically set coefficients, it turns out to be useful to operate with some, albeit simple, theoretical apparatus. The search model is a kind of simplification of reality, on the basis of which a formula is obtained (by itself, nobody needs it) that allows the program to decide which document to consider as found and how to rank it. After accepting the model, the coefficients often acquire a physical meaning and become clearer to the developer himself, and it becomes more interesting to select them.
All variety of traditional information retrieval models (IR) It is customary to divide into three types: set-theoretic (Boolean, fuzzy sets, extended Boolean), algebraic (vector, generalized vector, latent-semantic, neural network) and probabilistic.
The Boolean family of models is, in fact, the first one that comes to mind for a programmer implementing a full-text search. There is a word - the document is considered found, no - not found. Actually, the classical Boolean model is a bridge connecting the theory of information retrieval with the theory of search and data manipulation.
The criticism of the Boolean model, quite fair, is its extreme rigidity and unsuitability for ranking. Therefore, back in 1957, Joyce and Needham proposed to take into account the frequency characteristics of words, so that "... the comparison operation would be the ratio of the distance between vectors ..." (Joyce, 1957). Vector model and was successfully implemented in 1968 by the founding father of information retrieval science, Gerard Salton (GerardSalton) in the search engine SMART(Salton"sMagicalAutomaticRetrieverofText) .
The ranking in this model is based on the natural statistical observation that the higher the local frequency of a term in a document (TF) and more "rarity" (i.e. reverse occurrence in documents) of the term in the collection (IDF) , the higher the weight of the given document in relation to the term. Designation IDF introduced by Karen Spark-Jones in 1972 in an article on distinctive power (termspecificity) . From now on, the designation TF*IDF widely used as a synonym for vector model.
Finally, in 1977, Robertson and Spark-Jones substantiated and implemented a probabilistic model (proposed back in 1960 (Maron)), which also laid the foundation for a whole family. Relevance in this model is considered as the probability that a given document may be of interest to the user. This implies the existence of an already existing initial set of relevant documents, selected by the user or obtained automatically under some simplified assumption. The probability of being relevant for each subsequent document is calculated based on the ratio of the occurrence of terms in the relevant set and in the rest, "irrelevant" part of the collection. Although probabilistic models have some theoretical advantage—they arrange documents in descending order of “probability of being relevant”—in practice they have not been widely adopted.
I'm not going to go into details and write out cumbersome formulas for each model. Their summary, together with the discussion, occupies 35 pages in a compressed form in the book "Modern Information Retrieval" (Baeza-Yates). It is only important to note that in each of the families the simplest model proceeds from the assumption of the mutual independence of words and has a simple filtering condition: documents that do not contain the query word are never found. Advanced ("alternative") models of each of the families do not consider the words of the query to be mutually independent, and in addition, they allow finding documents that do not contain a single word from the query.
Search "by meaning"
The ability to find and rank documents that do not contain words from a query is often considered a sign of artificial intelligence or search by meaning and is a priori attributed to the advantages of the model. The question of whether this is so or not, we will leave beyond the scope of this article.
For example, I will describe only one, perhaps the most popular model that works according to the meaning. In information retrieval theory, this model is usually called latent semantic indexing (in other words, revealing hidden meanings). This algebraic model is based on the singular value decomposition of a rectangular matrix that associates words with documents. The element of the matrix is the frequency response, which reflects the degree of connection between the word and the document, for example, TF*IDF. Instead of the original million-dimensional matrix, the authors of the Furnas and Dirvester method proposed using 50-150 "hidden meanings" corresponding to the first principal components of its singular value decomposition.
Singular value decomposition of a real matrix A sizes m*n is called any decomposition of the form A= USV, where U m*m, V - orthogonal size matrix n*n, S- Diagonal Dimension Matrix m*n, whose elements sij = 0 , if i not equal j, And sii= si >= 0 . Quantities si are called the singular values of the matrix and are equal to the arithmetic values of the square roots of the corresponding eigenvalues of the matrix AAT. In the English-language literature, the singular value decomposition is usually called SVD-decomposition.
It has long been proved (Eckart) that if we leave the first k singular numbers (the rest equate to zero), we get the closest of all possible approximations of the original rank matrix k(in a sense, her "closest semantic interpretation of rank k"). By lowering the rank, we filter out irrelevant details; increasing, we try to reflect all the nuances of the structure of real data.
The operations of searching or finding similar documents are greatly simplified, since each word and each document is associated with a relatively short vector of k meanings (rows and columns of the corresponding matrices). However, due to the low meaningfulness of "meanings" or for some other reason, but the use LSI in the forehead for the search has not received distribution. Although for auxiliary purposes (automatic filtering, classification, separation of collections, preliminary dimensionality reduction for other models), this method seems to be used.
Quality control
“... a stability test showed that the overlap of relevant documents between any two assessors is approximately 40% on average<...>accuracy and recall, measured between assessors, about 65%<...>This imposes a practical upper bound on search quality in the region of 65%...”
("What we have learned, and not learned, from TREC", Donna Harman)
Whatever the model, the search engine needs "tuning" - assessing the quality of the search and setting parameters. Quality assessment is an idea fundamental to search theory. For it is thanks to the assessment of quality that one can speak about the applicability or inapplicability of a particular model and even discuss their theoretical aspects.
In particular, one of the natural limitations of the quality of the search is the observation made in the epigraph: the opinions of two "assessors" (specialists who make a verdict on relevance) on average do not coincide with each other to a very large extent! This implies a natural upper bound on the quality of the search, because the quality is measured by the results of comparison with the opinion of the assessor.
“...I was shocked when someone from Googletold me that they don't use anything from TREC at all, because all the algorithms sharpened on the “arbitrary requests” track are shattered by spam ... "
It's time to return to the topic with which this article began: what has changed in search engines lately?
First of all, it became obvious that a web search cannot be performed correctly in any way, being based on an analysis (even arbitrarily deep, semantic, etc.) of the document text alone. After all, non-textual (off-page) factors play no less, and sometimes even more role than the text of the page itself. Position on the site, attendance, authority of the source, update frequency, citation of the page and its authors - all these factors cannot be discounted.
Having become the main source of reference information for the human species, search engines have become the main source of traffic for Internet sites. As a result, they were immediately subjected to "attacks" by unscrupulous authors who wanted to be in the first pages of search results at any cost. Artificially generated entry pages saturated with popular words, cloaking techniques, blind text, and many other tricks designed to deceive search engines instantly flooded the Internet.
In addition to the problem of correct ranking, the creators of search engines on the Internet had to solve the problem of updating and synchronizing a colossal collection with heterogeneous formats, delivery methods, languages, encodings, a mass of meaningless and duplicated texts. It is necessary to maintain the database in a state of maximum freshness (in fact, it is enough to create the illusion of freshness - but this is a topic for a separate discussion), perhaps taking into account the individual and collective preferences of users. Many of these tasks have never before been considered in the traditional science of information retrieval.
For example, consider a couple of such tasks and practical ways to solve them in search engines for the Internet.
Ranking Quality
Not all non-textual criteria are equally useful. It was the link popularity and its derivatives that turned out to be the decisive factor that changed in 1999-2000. world of search engines and returned to them the devotion of users. Since it was with its help that search engines learned to decently and independently (without props from manually edited results) rank responses to short-frequency queries that make up a significant part of the search flow.
The simplest idea of global (ie static) link popularity accounting is to count the number of links pointing to pages. Approximately what in traditional library science is called a citation index. This criterion was used in search engines even before 1998. However, it is easily subjected to winding, in addition, it does not take into account the weight of the sources themselves.
The algorithm proposed by Brin and Page in 1998 can be considered a natural development of this idea. PageRank- an iterative algorithm similar to that used in the problem of determining the winner in a Swiss chess tournament. Combined with searching for the vocabulary of links pointing to a page (an old, very productive idea that was used in hypertext search engines back in the 80s), this measure allowed a dramatic improvement in the quality of search.
A little earlier than PageRank, a local (i.e. dynamic, query-based) popularity accounting algorithm has been proposed - HITS(Kleinberg), which is not used in practice mainly because of the computational cost. Approximately for the same reason as local (i.e. dynamic) methods that operate on words.
Both algorithms, their formulas, convergence conditions are described in detail, including in the Russian-language literature. I will only note that the calculation of static popularity is not a task in itself, it is used for numerous auxiliary purposes: determining the order of bypassing documents, ranking the search by the text of links, etc. Popularity calculation formulas are constantly improved, they include additional factors - thematic proximity of documents (for example, a popular search engine www.teoma.com), their structure, etc., allowing to reduce the influence of nepotism. An interesting separate topic is the efficient implementation of appropriate data structures (Bharat).
Index quality
Although the size of the database on the Internet at a superficial glance does not seem to be a critical factor, it is not. No wonder the growth in attendance of such machines as Google And Fast, correlates well precisely with the growth of their bases. The main reasons: "rare" requests, that is, those for which there are less than 100 documents, total about 30% of the total mass of searches - a very significant part. This fact makes the database size one of the most critical system parameters.
However, the growth of the base, in addition to technical problems with disks and servers, is also limited by logical ones: the need to adequately respond to garbage, repetitions, etc. I can't help but describe the ingenious algorithm used by modern search engines to exclude "very similar documents".
The origin of copies of documents on the Internet can be different. The same document on the same server may differ for technical reasons: it may be presented in different encodings and formats, it may contain variable inserts - advertising or the current date.
A wide class of documents on the web is actively copied and edited - news feeds, documentation and legal documents, store price lists, answers to frequently asked questions, and so on. Popular types of changes: proofreading, reorganization, revision, summarizing, topic disclosure, etc. Finally, publications may be copied in violation of copyright and maliciously modified to make them more difficult to detect.
In addition, indexing by search engines of pages generated from databases gives rise to another common class of outwardly little different documents: questionnaires, forums, product pages in electronic stores.
Obviously, there are no particular problems with full repetitions, it is enough to store the checksum of the text in the index and ignore all other texts with the same checksum. However, this method does not work to detect even slightly modified documents.
To solve this problem, Udi Manber (the author of the well-known approximate direct search program agrep) in 1994 proposed the idea, and Andrey Broder in 1997 came up with the name and brought to mind the shingles algorithm (from the word shingles- "tiles, scales"). Here is a rough description of it.

For each ten word of the text, a checksum (shingle) is calculated. The Decalogues are overlapping, overlapping, so that none is missing. And then, from the entire set of checksums (obviously, there are as many of them as there are words in the document minus 9), only those that are divisible by, say, 25 are selected. Since the values of the checksums are evenly distributed, the selection criterion is not tied to the features of the text. It is clear that the repetition of even a single ten words is a significant sign of duplication, but if there are many of them, say, more than half, then with a certain (it is easy to estimate the probability) certainty: a copy has been found! After all, one matched shingle in the sample corresponds to approximately 25 matched ten-words in the full text!
Obviously, this way you can determine the percentage of text overlap, identify all its sources, etc. This graceful algorithm has embodied the old dream of associate professors: from now on, the painful question “from whom the student copied this term paper” can be considered resolved! It is easy to estimate the share of plagiarism in any article.
So that the reader does not get the impression that information retrieval is an exclusively Western science, I will mention an alternative algorithm for determining almost-duplicates, invented and implemented in Yandex (Ilyinsky). It takes advantage of the fact that most search engines already have an inverted file index (or inverted index), and this fact is useful for finding near-duplicates.
The price of one percent
Architecturally modern search systems are complex multi-computer complexes. Starting from a certain moment, as the system grows, the main load falls not on the robot at all, but on the search. Indeed, within a second, tens and hundreds of requests come.
In order to cope with this problem, the index is divided into parts and spread over tens, hundreds and even thousands of computers. Computers themselves since 1997 (search engine Inktomi) are regular 32-bit machines ( linux, Solaris, FreeBSD, Win32 ) with corresponding price and performance constraints. The only exception to the general rule is AltaVista, which used relatively "large" 64-bit computers from the beginning Alpha.
Web search engines (and all major search engines in general) can speed up their work with separation and pruning techniques.
The first technique consists in dividing the index into obviously more relevant and less relevant parts. The search is first performed in the first part, and then, if nothing or little is found, the search engine turns to the second part of the index. Prune (from English. pruning- “cutting, reduction”) is to dynamically stop processing the request after the accumulation of a sufficient amount of relevant information. There is also static pruning, when, on the basis of some assumptions, the index is reduced due to such documents that will certainly never be found.
A separate problem is to organize the uninterrupted operation of multicomputer complexes, seamless updating of the index, resistance to failures and delays in the responses of individual components. For communication between search servers and servers that collect responses and form the issuance page, special protocols are being developed.
Note that one percent of the performance (say, a poorly written statement in some loop) for a ten thousand computer system costs about a hundred computers. Therefore, one can imagine how the code responsible for searching and ranking results is cleaned up, how the use of all possible resources is optimized: each byte of memory, each disk access.
Thinking through the architecture of the entire complex from the very beginning is crucial, since any changes - for example, adding an unusual ranking factor or a complex data source - become extremely painful and complex procedure. Obviously, systems that start later have an advantage in this situation. But the inertia of users is very high: for example, it takes two to four years for the formed multi-million audience to itself, albeit slowly, switch to an unusual search engine, even if it has undeniable advantages. In a highly competitive environment, this is sometimes not feasible.
Syntactic Clustering of the Web
Andrei Z. Broder, Steven C. Glassman, Mark S. Manasse
WWW6, 1997
The Approximation of One Matrix by Another of Lower Rank
Eckart, G. Young Psychometrica, 1936
Description and Performance Analysis of Signature File Methods
Faloutsos, S. Christodoulakis
ACM TOIS, 1987
Information Retrieval Using a Singular Value Decomposition Model of Latent Semantic Structure
G.W. Furnas, S. Deerwester, S.T. Dumais, T.K. Landauer, R.A. Harshman, L.A. Streeter and K.E. Lochbaum
ACM SIGIR, 1988
Examples of PAT Applied to the Oxford English Dictionary
Gonnet G.
University of Waterloo, 1987
The Thesaurus Approach to Information Retrieval
T. Joyce and R.M. Needham
American Documentation, 1958
An Efficient Method to Detect Duplicates of Web Documents with the Use of Inverted Index
S. Ilyinsky, M. Kuzmin, A. Melkov, I. Segalovich
WWW2002, 2002
Suffix Arrays: A New Method for On-line String Searches
U. Manber, G. Myers
1st ACM-SIAM Symposium on Discrete Algorithms, 1990
Finding Similar Files in a Large File System
U. Manber
USENIX Conference, 1994
On Relevance, Probabilistic Indexing and Information Retrieval
M.E. Maron and J.L. Kuhns
Journal of the ACM, 1960
Relevance Weighting of Search Terms
S.E. Robertson and K. Sparck Jones
JASIS, 1976
Algorithms in C++
Robert Sedgewick
Addison-Wesley, 1992
A Statistical Interpretation of Term Specificity and Its Application in Retrieval
K. Sparck Jones
Journal of Documentation, 1972
Natural Language Information Retrieval
Tomek Strzalkowski (ed.)
Kluwer Academic Publishers, 1999
Symphony, or Dictionary-Index to the Holy Scriptures of the Old and New Testaments
Compiled by M.A. Bondarev, M.S. Kosyan, S.Yu. Kosyan
Publishing House of the Moscow Patriarchy, 1995
Glossary
Assessor (assessor, expert) - a specialist in the subject area who makes a conclusion about the relevance of the document found by the search engine.
boolean model (boolean, boolean, boolean, binary) is a search model based on the operations of intersection, union and subtraction of sets.
vector pattern- an information retrieval model that considers documents and queries as vectors in the word space, and relevance as the distance between them.
Probabilistic model- an information retrieval model that considers relevance as the probability of a given document matching a query based on the probabilities of matching the words of a given document to an ideal answer.
Out-of-text criteria (off-page, off-page) - criteria for ranking documents in search engines, taking into account factors that are not contained in the text of the document itself and cannot be extracted from there in any way.
Entry pages (doors, hallways) - pages created to artificially increase the rank in search engines (search engine spam). When they hit them, the user is redirected to the landing page.
Disambiguation (tagging, partofspeechdisambiguation, tagging) - selection of one of several homonyms using the context; in English is often reduced to the automatic assignment of the grammatical category "part of speech".
duplicates (duplicates) - different documents with identical, from the user's point of view, content; approximate duplicates (nearduplicates, near-duplicates), unlike exact duplicates, contain minor differences.
Illusion of freshness- the effect of apparent freshness achieved by search engines on the Internet due to the more regular bypass of those documents that are more often found by users.
Inverted file (invertedfile, inverse file, posting index, posting list) is a search engine index that lists the words of a collection of documents, and for each word, all the places where it occurs are listed.
Index (index, pointer) - see Indexing.
Citation Index (quoteindex) - the number of mentions (citations) of a scientific article in traditional bibliographic science is calculated over a period of time, for example, per year.
Indexing (indexing, indexing) - the process of compiling or assigning a pointer (index) - a service data structure necessary for subsequent search.
Information retrieval (InformationRetrieval, IR) - search for unstructured information, the representation unit of which is a document of arbitrary formats. The subject of the search is the information need of the user, informally expressed in the search query. Both the search criterion and its results are non-deterministic. In these features, information retrieval differs from "data retrieval", which operates on a set of formally specified predicates, deals with structured information, and whose result is always determined. Information retrieval theory studies all components of the search process, namely text preprocessing (indexing), query processing and execution, ranking, user interface and feedback.
cloaking (cloaking) - a search spam technique that consists in recognizing by the authors of documents a robot (indexing agent) of a search engine and generating special content for it, which is fundamentally different from the content given to the user.
Term Contrast- see Distinctive power.
Latent semantic indexing- a patented search algorithm by meaning, identical to factor analysis. It is based on the singular value decomposition of the word-to-document connection matrix.
Lemmatization (lemmatization, normalization) - bringing the form of a word to a dictionary form, that is, a lemma.
Search engine boost- see search engine spam.
Nepotism- a type of search engine spam, the installation of mutual links by the authors of documents for the sole purpose of increasing their rank in the search results.
Reverse occurrence in documents (inverteddocumentfrequency, IDF, reverse frequency in documents, reverse document frequency) - an indicator of the search value of a word (its distinctive power); They say “reverse” because when calculating this indicator, the denominator of the fraction is usually the number of documents containing the given word.
Feedback- users' response to the search result, their judgments about the relevance of the found documents, recorded by the search engine and used, for example, for iterative modification of the query. This should be distinguished from pseudo-feedback, a query modification technique in which the first few documents found are automatically considered relevant.
homonymy- see Polysemy.
The foundation- part of a word common to a set of its derivational and inflectional (more often) forms.
Search by meaning- an information retrieval algorithm capable of finding documents that do not contain query words.
Search for similar documents (similardocumentsearch) - the task of information retrieval, in which the document itself acts as a request and it is necessary to find documents that resemble the given one as much as possible.
Search system (searchengine, SE, information retrieval system, IPS, search engine, search engine, "search engine", "search engine") - a program designed to search for information, usually text documents.
Search order (query, query) - usually a line of text.
Polysemy (polysemy, ambiguity) - the presence of several meanings for the same word.
completeness (recall, coverage) - the proportion of relevant material contained in the response of the search engine, in relation to all relevant material in the collection.
Almost-duplicates (near-duplicates, approximate duplicates) - see Duplicates.
pruning (pruning) - cutting off obviously irrelevant documents during the search in order to speed up the execution of the request.
Direct Search- search directly in the text of documents, without preliminary processing (without indexing).
Pseudo feedback- see Feedback.
Distinctive power of the word (termspecificity, termdiscriminationpower, contrast, distinctive power) - the degree of width or narrowness of the word. Too broad terms in the search bring too much information, while a significant part of it is useless. Too narrow terms help to find too few documents, although more accurate ones.
Regular expression (regularexpression, pattern, "template", less often "stencil", "mask") - a way to record a search prescription that allows you to determine wishes for the word you are looking for, its possible spellings, errors, etc. In a broad sense, a language that allows you to set queries of unlimited complexity.
Relevance (relevance, relevance) - compliance of the document with the request.
Signature (signature, signature) - a set of hash values of words of some block of text. When searching by signature method all signatures of all blocks of the collection are searched sequentially in search of matches with the hash values of the query words.
inflection (inflation) - the formation of a form of a certain grammatical meaning, usually mandatory in a given grammatical context, belonging to a fixed set of forms (paradigm) characteristic of words of a given type. Unlike word formation, it never leads to a type change and generates a predictable meaning. The inflection of names is called declension. (declension) , and verbs - conjugation (conjugation) .
word formation (derivation) - the formation of a word or stem from another word or stem.
intelligible- see Distinctive power.
Search engine spam (spam, spamdexing, cheating search engines) - an attempt to influence the result of information retrieval by the authors of documents.
Static popularity- cm. PageRank.
stemming- the process of extracting the basis of the word.
Stop words (stop-words) - those conjunctions, prepositions and other frequent words that this search engine has excluded from the indexing and search process to improve its performance and / or search accuracy.
Suffix trees, suffix arrays (suffixtrees, suffixarrays, PAT-arrays) is an index based on the representation of all significant text suffixes in a data structure known as "boron" (trie) . suffix in this index, any "substring" is called, starting at some position of the text (the text is treated as one continuous line) and continuing to its end. In real applications, the length of suffixes is limited, and only significant positions are indexed - for example, the beginning of words. This index allows you to perform more complex queries than an index built on inverted files.
Tokenization (tokenization, lexicalanalysis, graphematic analysis, lexical analysis) - the selection of words, numbers and other tokens in the text, including, for example, finding the boundaries of sentences.
Accuracy (precision) - share of relevant material in the response of the search engine.
Hash value (hash-value) - meaning hash functions (hash-function) , which converts data of arbitrary length (usually a string) into a number of a fixed order.
Frequency (words) in documents (documentfrequency, occurrence in documents, document frequency) - the number of documents in the collection containing the given word.
Term frequency (termfrequency.TF) - frequency of use of the word in the document.
shingle (shingle) - hash value of a continuous sequence of text words of a fixed length.
PageRank- an algorithm for calculating the static (global) popularity of a page on the Internet, named after one of the authors - Lawrence Page. Corresponds to the probability of the user hitting the page in the random walk model.
TF*IDF- a numerical measure of the correspondence between a word and a document in a vector model; the more than relatively more often the word was found in the document and relatively less often- in the collection.
Why does a marketer need to know the basic principles of search engine optimization? It's simple: organic traffic is a great source of incoming target audience traffic for your corporate website and even landing pages.
Meet a series of educational posts on the topic of SEO.
What is a search engine?
The search engine is a large database of documents (content). Search robots bypass resources and index different types of content, it is these saved documents that are ranked in the search.
In fact, Yandex is a “cast” of the Runet (also Turkey and a few English-language sites), and Google is the global Internet.
A search index is a data structure containing information about documents and the location of keywords in them.
According to the principle of operation, search engines are similar to each other, the differences lie in the ranking formulas (ordering sites in search results), which are based on machine learning.
Every day, millions of users submit queries to search engines.
"Abstract to write":

"Buy":

But most interested in...

How is a search engine organized?
To provide users with quick answers, the search architecture was divided into 2 parts:
- basic search,
- metasearch.
Basic Search
Basic search - a program that searches its part of the index and provides all the documents that match the query.
Metasearch is a program that processes a search query, determines the user's regionality, and if the query is popular, then it gives out a ready-made search option, and if the query is new, it selects a basic search and issues a command to select documents, then ranks the found documents using machine learning and provides user.

Search query classification
To give a relevant answer to the user, the search engine first tries to understand what he specifically needs. The search query is analyzed and the user is analyzed in parallel.
Search queries are analyzed by parameters:
- Length;
- definition;
- popularity;
- competitiveness;
- syntax;
- geography.
Request type:
- navigation;
- informational;
- transactional;
- multimedia;
- general;
- official.
After parsing and classifying the query, the ranking function is selected.

The designation of request types is confidential information and the proposed options are the guesswork of search engine promotion specialists.
If the user sets a general query, then the search engine returns different types of documents. And it should be understood that by promoting the commercial page of the site in the TOP-10 for a general request, you are claiming to get not one of the 10 places, but the number of places
for commercial pages, which is highlighted by the ranking formula. And therefore, the probability of being ranked in the top for such requests is lower.
Machine learning MatrixNet is an algorithm introduced in 2009 by Yandex that selects the function of ranking documents for certain queries.

MatrixNet is used not only in Yandex search, but also for scientific purposes. For example, at the European Center for Nuclear Research, it is used for rare events in large amounts of data (they are looking for the Higgs boson).
Primary data for evaluating the effectiveness of the ranking formula is collected by the assessors department. These are specially trained people who evaluate a sample of sites according to an experimental formula according to the following criteria.
Site quality assessment
Vitalny - official site (Sberbank, LPgenerator). The search query corresponds to the official website, groups in social networks, information on authoritative resources.
Useful (score 5) - a site that provides extended information upon request.
Example - request: banner fabric.
A site corresponding to the "useful" rating should contain information:
- what is banner fabric;
- specifications;
- Photo;
- kinds;
- price list;
- something else.
Top request examples:

Relevant+ (Score 4) - This score means that the page matches the search query.
Relevant- (Score 3) - The page does not exactly match the search query.
Let's say that the search for "Guardians of the Galaxy sessions" displays a page about a movie without screenings, a page of a past session, a page of a trailer on youtube.
Irrelevant (Score 2) - The page does not match the query.
Example: the name of the hotel displays the name of another hotel.
To promote a resource for a general or informational request, you need to create a page corresponding to the “useful” rating.
For clear queries, it is enough to meet the "relevant+" score.
Relevance is achieved through textual and link matching of the page with search queries.
conclusions
- Not all queries can promote a commercial landing page;
- Not all information requests can be used to promote a commercial site;
- By promoting a general request, create a useful page.
A common reason why a site does not reach the top is that the content of the promoted page does not match the search query.
We will talk about this in the next article “Checklist for basic website optimization”.
Hello dear readers!
There are quite a lot of search engines in the global Internet space at the moment. Each of them has its own algorithms for indexing and ranking sites, but in general, the principle of operation of search engines is quite similar.
Knowledge of how the search engine works in the face of rapidly growing competition is a significant advantage when promoting not only commercial, but also informational sites and blogs. This knowledge helps to build an effective website optimization strategy and get into the TOP search results for promoted query groups with less effort.
Search engine principles
The purpose of the optimizer is to "adjust" promoted pages to search algorithms and, thereby, help these pages achieve high positions for certain queries. But before starting work on optimizing a site or blog, it is necessary to at least superficially understand the features of the work of search engines in order to understand how they can react to the actions taken by the optimizer.
Of course, the detailed details of the formation of search results are information that search engines do not disclose. However, for the right efforts, it is enough to understand the main principles by which search engines work.
Information search methods
The two main methods used by search engines today differ in their approach to finding information.
- Direct Search Algorithm, which involves matching each of the documents stored in the database of the search engine with a key phrase (user request), is a fairly reliable method that allows you to find all the necessary information. The disadvantage of this method is that when searching through large datasets, the time required to find the answer is quite long.
- Reverse Index Algorithm, when a list of documents in which it is present is compared to a key phrase, is convenient when interacting with databases containing tens and hundreds of millions of pages. With this approach, the search is performed not on all documents, but only on special files that include lists of words contained on site pages. Each word in such a list is accompanied by an indication of the coordinates of the positions where it occurs, and other parameters. It is this method that is used today in the work of such well-known search engines as Yandex and Google.
It should be noted here that when a user accesses the browser's search bar, the search is not performed directly on the Internet, but in previously collected, saved and current databases containing blocks of information processed by search engines (website pages). Quick generation of search results is possible thanks to working with reverse indexes.

The text content of the pages (direct indexes) is also stored by search engines and used in the automatic generation of snippets from text fragments that are most suitable for the query.
Mathematical model of ranking
In order to speed up the search and simplify the process of generating the issue that best meets the user's request, a certain mathematical model is used. The task of this mathematical model is to find the necessary pages in the current database of reverse indexes, evaluate their degree of compliance with the query and distribute them in descending order of relevance.
Just finding the right phrase on the page is not enough. When determined by search engines, the calculation of the weight of the document relative to the user request is applied. For each request, this parameter is calculated based on the following data: the frequency of use on the analyzed page and a coefficient that reflects how rarely the same word occurs in other documents of the search engine database. The product of these two values corresponds to the weight of the document.
Of course, the presented algorithm is very simplified, since search engines have a number of other additional coefficients used in the calculations, but the meaning does not change. The more often a single word from the user's query occurs in any document, the higher the weight of the latter. At the same time, the text content of the page is considered spam if certain limits are exceeded, which are different for each request.
The main functions of the search engine
All existing search systems are designed to perform several important functions: information retrieval, its indexing, quality assessment, correct ranking and search results generation. The primary task of any search engine is to provide the user with the information he is looking for, the most accurate answer to a specific request.
Since most users have no idea how Internet search engines work, and the ability to teach users the “correct” search is very limited (for example, with search suggestions), developers are forced to improve the search itself. The latter implies the creation of algorithms and principles of operation of search engines that allow finding the required information, regardless of how “correctly” the search query is formulated.
Scanning
This is tracking changes in already indexed documents and searching for new pages that can be presented in the results of issuing user requests. Search engines scan resources on the Internet using specialized programs called spiders or search robots.
Scanning of Internet resources and data collection is performed by search bots automatically. After the first visit to the site and its inclusion in the search database, robots begin to periodically visit this site in order to track and record the changes that have occurred in the content.
Since the number of developing resources on the Internet is large, and new sites appear daily, the described process does not stop for a minute. This principle of operation of search engines on the Internet allows them to always have up-to-date information about the sites available on the network and their content.
The main task of the search robot is to search for new data and transfer it to the search engine for further processing.

Indexing
The search engine is able to find data only on sites presented in its database - in other words, indexed. At this step, the search engine must determine whether the found information should be entered into the database and, if so, into which section. This process is also performed automatically.
It is believed that Google indexes almost all information available on the network, while Yandex approaches content indexing more selectively and not so quickly. Both search giants of the Runet work for the benefit of the user, but the general principles of the Google and Yandex search engines are somewhat different, as they are based on the unique software solutions that make up each system.
The common point for search engines is that the process of indexing all new resources takes longer than indexing new content on sites known to the system. Information that appears on sites that are highly trusted by search engines gets into the index almost instantly.
Ranging
Ranking is an assessment by search engine algorithms of the significance of indexed data and alignment of them in accordance with factors specific to this search engine. The received information is processed in order to generate search results for the entire range of user requests. What kind of information will be presented in the search results above and what below is completely determined by how the selected search engine and its algorithms work.
Sites that are in the base of the search engine are distributed according to topics and groups of requests. For each group of requests, a preliminary issuance is formed, which is subject to further adjustment. The positions of most sites change after each update of the issuance - updating the ranking, which happens daily in Google, in Yandex search - once every few days.
Man as an assistant in the struggle for the quality of issuance
The reality is that even the most advanced search engines, such as Yandex and Google, currently still need human help to generate results that meet accepted quality standards. Where the search algorithm does not work well enough, its results are corrected manually - by evaluating the content of the page against a variety of criteria.
A large army of specially trained people from different countries - moderators (assessors) of search engines - have to do a huge amount of work every day to check the compliance of site pages with user requests, filtering spam and prohibited content (texts, images, videos). The work of assessors allows you to make the issuance cleaner and contributes to the further development of self-learning search algorithms.

Conclusion
With the development of the Internet and the gradual change in standards and forms of content presentation, the approach to search is also changing, the processes of indexing and ranking information, the algorithms used are being improved, and new ranking factors are emerging. All this allows search engines to generate the most high-quality and adequate results for user requests, but at the same time complicates the life of webmasters and website promotion specialists.
In the comments under the article, I propose to speak about which of the main search engines of the Runet - Yandex or Google, in your opinion, works better, providing the user with a better search, and why.
What is it
DuckDuckGo is a fairly well-known open source search engine. The servers are located in the USA. In addition to its own robot, the search engine uses the results of other sources: Yahoo, Bing, Wikipedia.
The better
DuckDuckGo positions itself as the ultimate privacy and privacy search. The system does not collect any data about the user, does not store logs (no search history), the use of cookies is as limited as possible.
DuckDuckGo does not collect or share personal information from users. This is our privacy policy.
Gabriel Weinberg, founder of DuckDuckGo
Why do you need this
All major search engines try to personalize search results based on data about the person in front of the monitor. This phenomenon is called "filter bubble": the user sees only those results that are consistent with his preferences or that the system considers as such.
Forms an objective picture that does not depend on your past behavior on the Web, and gets rid of Google and Yandex thematic advertising based on your requests. With the help of DuckDuckGo, it is easy to search for information in foreign languages, while Google and Yandex prefer Russian-language sites by default, even if the query is entered in another language.

What is it
not Evil is a system that searches the anonymous Tor network. To use it, you need to go to this network, for example, by launching a specialized .
not Evil is not the only search engine of its kind. There is LOOK (default search in the Tor browser, accessible from the regular Internet) or TORCH (one of the oldest search engines on the Tor network) and others. We settled on not Evil because of the unmistakable allusion to Google (just look at the start page).
The better
He is looking for where Google, Yandex and other search engines are denied access in principle.
Why do you need this
There are many resources on the Tor network that cannot be found on the law-abiding Internet. And their number will grow as the control of the authorities over the contents of the Web tightens. Tor is a kind of network within the Web with its social networks, torrent trackers, media, marketplaces, blogs, libraries, and so on.
3. YaCy

What is it
YaCy is a decentralized search engine that works on the principle of P2P networks. Each computer on which the main software module is installed scans the Internet on its own, that is, it is an analogue of a search robot. The results obtained are collected in a common database, which is used by all YaCy participants.
The better
It is difficult to say here whether this is better or worse, since YaCy is a completely different approach to organizing search. The lack of a single server and owner company makes the results completely independent of anyone's preferences. The autonomy of each node excludes censorship. YaCy is capable of searching the deep web and non-indexed public networks.
Why do you need this
If you are a supporter of open source software and a free Internet that is not influenced by government agencies and large corporations, then YaCy is your choice. It can also be used to organize searches within a corporate or other autonomous network. And although YaCy is not very useful in everyday life, it is a worthy alternative to Google in terms of the search process.
4. Pipl

What is it
Pipl is a system designed to search for information about a specific person.
The better
The authors of Pipl claim that their specialized algorithms search more efficiently than "regular" search engines. In particular, social media profiles, comments, lists of members and various databases where information about people is published, such as databases of court decisions, are prioritized. Pipl's leadership in this area is confirmed by Lifehacker.com, TechCrunch and other publications.
Why do you need this
If you need to find information about a person living in the US, then Pipl will be much more efficient than Google. Databases of Russian courts, apparently, are inaccessible to the search engine. Therefore, he does not cope so well with the citizens of Russia.

What is it
FindSounds is another specialized search engine. Searches open sources for various sounds: house, nature, cars, people, and so on. The service does not support requests in Russian, but there is an impressive list of Russian-language tags that you can search for.
The better
In the issuance of only sounds and nothing more. In the settings you can set the desired format and sound quality. All found sounds are available for download. There is a pattern search.
Why do you need this
If you need to quickly find the sound of a musket shot, the blow of a sucking woodpecker, or the cry of Homer Simpson, then this service is for you. And we chose this only from the available Russian-language queries. In English, the spectrum is even wider.
Seriously, a specialized service implies a specialized audience. But will it come in handy for you too?

What is it
Wolfram|Alpha is a computational search engine. Instead of links to articles containing keywords, it gives a ready-made answer to the user's request. For example, if you enter “compare the population of New York and San Francisco” in English into the search form, then Wolfram|Alpha will immediately display tables and graphs with a comparison.
The better
This service is better than others for finding facts and calculating data. Wolfram|Alpha collects and organizes knowledge available on the Web from various fields, including science, culture and entertainment. If this database contains a ready answer to a search query, the system shows it, if not, it calculates and displays the result. In this case, the user sees only and nothing more.
Why do you need this
If you are, for example, a student, analyst, journalist, or researcher, you can use Wolfram|Alpha to find and calculate data related to your activities. The service does not understand all requests, but is constantly evolving and becoming smarter.

What is it
Metasearch engine Dogpile displays a combined list of results from Google, Yahoo and other popular search engines.
The better
First, Dogpile displays fewer ads. Secondly, the service uses a special algorithm to find and display the best results from different search engines. According to the developers of Dogpile, their system generates the most complete issue on the entire Internet.
Why do you need this
If you can't find information on Google or another standard search engine, look it up in several search engines at once using Dogpile.

What is it
BoardReader is a text search system for forums, Q&A services and other communities.
The better
The service allows you to narrow the search field to social sites. Thanks to special filters, you can quickly find posts and comments that match your criteria: language, publication date, and site name.
Why do you need this
BoardReader can be useful for PR specialists and other media professionals who are interested in the opinion of the mass media on certain issues.
Finally
The life of alternative search engines is often fleeting. Lifehacker asked the former CEO of the Ukrainian branch of the Yandex company Sergey Petrenko about the long-term prospects for such projects.

Sergey Petrenko
Former CEO of Yandex.Ukraine.
As for the fate of alternative search engines, it is simple: to be very niche projects with a small audience, therefore, without clear commercial prospects, or, conversely, with the complete clarity of their absence.
If you look at the examples in the article, you can see that such search engines either specialize in a narrow but in-demand niche, which, perhaps only so far, has not grown enough to be noticeable on the radars of Google or Yandex, or are testing an original hypothesis in ranking, which is not yet applicable in conventional search.
For example, if a Tor search suddenly turns out to be in demand, that is, at least a percentage of the Google audience will need the results from there, then, of course, ordinary search engines will begin to solve the problem of how to find them and show them to the user. If the behavior of the audience shows that a significant proportion of users in a significant number of queries seem to be more relevant results, data without taking into account factors that depend on the user, then Yandex or Google will begin to give such results.
"To be better" in the context of this article does not mean "to be better at everything". Yes, in many aspects our heroes are far from Yandex (even far from Bing). But each of these services gives the user something that the giants of the search industry cannot offer. Surely you also know similar projects. Share with us - let's discuss.
Good afternoon, dear readers of my SEO blog . This article is about how the Yandex search engine works what technologies and algorithms it uses to rank sites, what it does to prepare a response to users. Many people know that this flagship of the Russian search sets the tone in Runet, owns the largest database in Eurasia, operates on the content of more than a billion pages, knows the answer to any question. According to Liveinternet data for August 2012, Yandex's share in Russia is 60.5%. The monthly audience of the portal is 48.9 million people. But the most important thing for us bloggers is how the search engine receives our requests, how they process them and what the result is. On the one hand, knowing and understanding this information, it is easier for us to use all Yandex resources, on the other hand, it is easier to promote our blogs. Therefore, I propose to look with me at the most important technologies of the best search engine on the Runet.
When an Internet user first wants to turn to a search engine for information, he may have one question: “How does the search work?” But when he receives it, often this question changes to another: “Why so quickly?” And really, why does it take 20 seconds to search for a file on a computer, but the result of a query from an entire network of computers around the world appears in a second? The most interesting thing is that the first two questions (how the search works and why 1 second) can be in one answer - the search engine has prepared in advance for the user's request.
To understand the principle of Yandex, as well as other search engines, let's draw an analogy with a telephone directory. To find any phone number, you need to know the name of the subscriber and any search in this case takes a maximum of a minute, because all the pages of the directory are a continuous alphabetical index. But imagine if the search went according to another option, where phone numbers would be ordered by the numbers themselves. After such searches, which will already drag on for a longer time, the figures will remain in front of the eyes of the seeker for a very long time. 🙂
So the search engine lays out all the information from the Internet in a form convenient for it. And most importantly, all this data is placed in advance in her directory, before the visitor arrives with their requests. That is, when we ask Yandex a question, it already knows our answer. And gives it to us in a second. But this second includes a number of important processes, which we will now consider in detail.
Internet indexing
Yandex ru collects on the Internet all the information that it can reach. With the help of special equipment, all content is viewed, including images according to visual parameters. The search engine is engaged in such collection, and the process of collecting and preparing data is called indexing. The basis of such a machine is a computer system, which is otherwise called a search robot. It regularly crawls indexed sites, checks them for new content, and also scans the Internet for deleted pages. If it detects that some such page no longer exists or is closed from indexing, then it removes it from the search.
How does a search robot find new sites? First, thanks to links from other sites. Because if a link is placed on a new web resource from an already indexed site, then the next time you visit the second one, the robot will visit the first one as well. Secondly, there is a wonderful service, popularly called "addurilka" (from the phrase in English -addurl - add an address). In it, you can enter the address of your new site, which after a while will be visited by the search robot. Thirdly, with the help of a special Yandex.Bar program, the visits of users who use it are tracked. Accordingly, if a person has landed on a new web resource, a robot will soon appear there.
Do all pages appear in search? Millions of pages are indexed every day. Among them there are pages of different quality, which may contain different information - from unique content to complete garbage. Moreover, according to statistics, there is much more garbage on the Internet. The search robot analyzes each document using special algorithms. It determines if it has any useful information, if it can answer the user's request. If not, then such pages are not taken “astronauts”, but if so, then it is included in the search.
After the robot has visited the page and determined its usefulness, it appears in the search engine storage. Here is the analysis of any document to the very basics, as the masters of the auto center say - to the cogs. The page is cleared of html markup, the clean text goes through a complete inventory - the location of each word is calculated. In this disassembled form, the page turns into a table with numbers and letters, which is otherwise called an index. Now, whatever happens to the web resource that contains this page, its latest copy is always in the search. Even if the site no longer exists, copies of its documents are still stored on the Internet for some time.
Each index, together with data on document types, encoding, language, together with copies, constitute search base . It is updated periodically, therefore it is located on special servers, with the help of which the requests of search engine users are processed.
How often does the indexing process take place? First of all, it depends on the types of sites. A web resource of the first type very often changes the content of its pages. That is, when a search robot comes to these pages each time, they each time contain different content. You won't be able to find anything on them next time, so such sites are not included in the index. The second type of sites are data warehouses, on the pages of which links to documents for downloading are periodically added. The content of such a site usually does not change, so the robot rarely visits it. Other sites depend on how often the material is updated. This means the following - the faster new content appears on the site, the more often the search robot comes. And priority is given first of all to the most important web resources (a news site is an order of magnitude more important than any blog, for example).
Indexing allows you to perform the first function of a search engine - the collection of information on new pages on the Internet. But Yandex also has a second function - searching for an answer to a user's request in an already prepared search database.
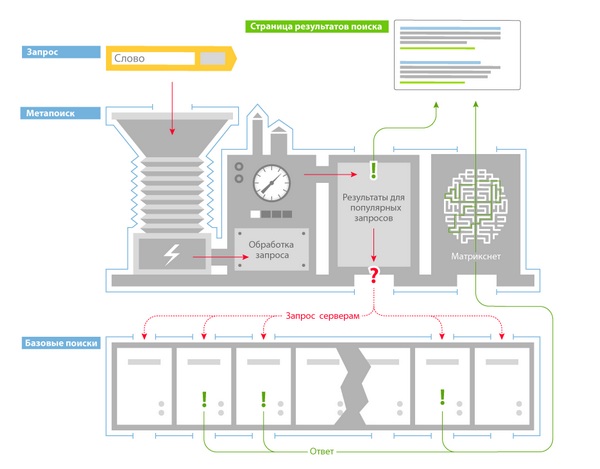
Yandex is preparing a response
The process of processing the request and issuing relevant responses is handled by computer system "Metapoisk" . For its work, it first collects all the introductory information: what region the request was made from, what class it belongs to, whether there are errors in the request, etc. After such processing, metasearch checks if there are exactly the same queries with the same parameters in the database. If the answer is yes, then the system shows the user the previously saved results. If such a question does not exist in the database, metasearch refers to the search database that contains the index data.
And this is where amazing things happen. Imagine that there is one super-powerful computer that stores the entire Internet processed by search robots. The user sets a request and the search for all documents involved in the request begins in the memory cells. The answer is found and everyone is happy. But let's take another case, when there are a lot of requests containing the same words in their body. The system has to go through the same memory cells every time, which can increase the time for data processing at times. Accordingly, the time increases, which can lead to the loss of the user - he will turn to another search engine for help.
To avoid such delays, all copies in the site index are distributed over different computers. After sending the request, metasearch instructs such servers to search for their piece with text. After that, all the data from these machines is returned to the central computer, it combines all the results and gives the user the top ten best answers. With this technology, two birds with one stone are immediately killed: the search time is reduced several times (the answer is obtained in a split second) and due to the increase in sites, information is duplicated (data is not lost due to sudden breakdowns). The computers themselves with duplicate information make up the data center - this is a room with servers.

When a search engine user submits their query, 20 out of 100 times there are ambiguous targets in the question. For example, if he writes the word "Napoleon" in the search bar, then it is not yet known what answer awaits - a cake recipe or a biography of the great commander. Or the phrase "The Brothers Grimm" - fairy tales, films, a musical group. In order to narrow down such a possible fan of goals to specific answers, Yandex has a special technology Range. It takes into account the needs of users using search query statistics. Of all the questions asked in Yandex by visitors, Spectrum singles out various objects in them (names of people, titles of books, models of cars, etc.). These objects are divided into certain categories. To date, there are more than 60 such categories. With the help of them, the search engine has in its database different meanings of words in user queries. Interestingly, these categories are periodically checked (the analysis takes place a couple of times a week), which allows Yandex to more accurately answer the questions posed.
Based on Spectrum technology, Yandex organized dialog prompts. They appear below the search bar in which the user types their ambiguous query. This line reflects the categories that the question object can belong to. Further search results depend on the user's choice of such a category.
 From 15 to 30% of all users of the Yandex search engine want to receive only local information (data from the region in which they live). For example, about new films in the cinemas of your city. Therefore, the answer to such a request should be different for each region. In this regard, Yandex uses its technology search based on regions
. For example, here are the answers that residents who are looking for a repertoire of films in their Oktyabr cinema can get:
From 15 to 30% of all users of the Yandex search engine want to receive only local information (data from the region in which they live). For example, about new films in the cinemas of your city. Therefore, the answer to such a request should be different for each region. In this regard, Yandex uses its technology search based on regions
. For example, here are the answers that residents who are looking for a repertoire of films in their Oktyabr cinema can get:

And this is the result that residents of the city of Stavropol will receive for the same request:

The region of the user is determined primarily by his ip-address. Sometimes this data is not accurate, because a number of providers can work for several regions at once, and therefore change the ip-addresses of their users. In principle, if this happened to you, you can easily change your region in the settings in the search engine. It is listed in the upper right corner on the results page. You can change it.
Yandex ru search engine - response results
When Metapoisk has prepared an answer, the Yandex search engine should display it on the results page. It is a list of links to found documents with a little information about each. The task of the results delivery technology is to provide the user with the most relevant answers as informative as possible. The template for one such link looks like this:

Let's consider this form of the result in more detail. For search result header Yandex often uses the name of the page title (what optimizers write in the title tag). If it is not there, then the words from the title of the article or post appear here. If the title text is large, the search engine puts in this field its fragment, which is most relevant to the given query.
Very rarely, but it happens that the title does not match the content of the request. In this case, Yandex generates its own search result title using the text in the article or post. It will definitely have query words.
For snippet the search engine uses all the text on the page. It selects all fragments where the response to the query is present, and then selects the most relevant of them and inserts links to the document into the form field. Thanks to this approach, a competent optimizer can remake the snippet after seeing it, thereby improving the attractiveness of the link.
For a better perception of the result to the user's request, the headings are formatted as links in the text (highlighted in blue with underlining). For the attractiveness of the web resource and its recognition, a favicon is added - a small corporate icon of the site. It appears to the left of the text on the first line before the heading. All the words that were included in the request in the response are also in bold for ease of perception.
Recently, the Yandex search engine has added various information to the snippet, which will help the user find his answer even faster and more accurately. For example, if a user writes the name of an organization in his request, then Yandex will add its address, contact numbers and a link to the location in geographic maps in the snippet. If the search engine is familiar with the structure of the site, which has a document with an answer for the user, it will definitely show it. Plus, Yandex can immediately add the most visited pages of such a web resource to the snippet so that, if desired, the visitor can immediately go to the section he needs, saving his time.
There are snippets that contain the price of a product for an online store, the rating of a hotel or restaurant in the form of stars, and other interesting information with various numbers about objects in search documents. The task of such information is to give a complete list of data about those subjects or objects that are of interest to the user.
In general, already with various examples, the answer page will look like this:

Ranking and Assessors
Yandex's task is not only to search for all possible answers, but also to select the best (relevant) ones. After all, the user will not rummage through all the links that Yandex will provide him as a search result. The process of ordering search results is called ranking . That is, it is the ranking that determines the quality of the proposed answers.
There are rules by which Yandex determines relevant pages:
- a decrease in positions on the results page is waiting for sites that degrade the quality of the search. Usually these are web resources whose owners are trying to deceive the search engine. For example, these are sites with pages that contain meaningless or invisible text. Of course, it is visible and understandable to the search robot, but not to the visitor reading this document. Or sites that, when clicking on a link in the search results area, immediately transfer the user to a completely different site.
- sites containing erotic content do not get into the results or are greatly reduced in ranking. This is due to the fact that such web resources often use aggressive promotion methods.
- sites infected with viruses are not lowered in search results and are not excluded from search results - in this case, the user is informed about the danger using a special icon. This is due to the fact that Yandex assumes that such web resources may contain important documents at the request of a search engine visitor.
For example, this is how Yandex will rank sites for the query "apple":

In addition to ranking factors, Yandex uses special samples with requests and responses that search engine users consider the most appropriate. No machine can make such samples at the moment - this is the prerogative of man. In Yandex, such specialists are called assessors. Their task is to fully analyze all search documents and evaluate responses to given queries. They choose the best answers and make a special training sample. In it, the search engine sees the relationship between relevant pages and their properties. With this information, Yandex can choose the optimal ranking formula for each request. The method of constructing such a formula is called Matrixnet. The advantage of this system is that it is resistant to overfitting, which allows you to take into account a large number of ranking factors without increasing the number of unnecessary estimates and patterns.
At the end of my post, I want to show you some interesting statistics collected by the Yandex search engine in the course of its work.
1. The popularity of personal names in Russia and Russian cities (data taken from blogger and social media accounts in March 2012).


 In 1863, the great writer Jules Verne created his next book, Paris in the 20th Century. In it, he described in detail the subway, the car, the electric chair, the computer, and even the Internet. However, the publisher refused to print the book and it sat for more than 120 years until Jules Verne's great-grandson found it in 1989. The book was published in 1994.
In 1863, the great writer Jules Verne created his next book, Paris in the 20th Century. In it, he described in detail the subway, the car, the electric chair, the computer, and even the Internet. However, the publisher refused to print the book and it sat for more than 120 years until Jules Verne's great-grandson found it in 1989. The book was published in 1994.





